
⚡ エグゼクティブ・サマリー
- BroadcomのAI収益がFY2027に$100億超え(≒15兆円超)を射程に——Hock TanCEOが公式に「significantly in excess of $100 billion」を宣言。
- Google・Meta・Anthropic・OpenAIら6社のカスタムXPU需要が爆発的に拡大——汎用GPUへの依存を断ち切ろうとするハイパースケーラーの動きがBroadcomの背中を押している。
- チップ単体にとどまらず”ラックごと売る”戦略へ転換——OEM/ODMを中抜きするモデルは、SupermicroやDellなど既存インフラベンダーへの脅威となり得る。
【前提知識】既存テクノロジーの限界と課題
なぜ汎用GPUだけでは限界が来ているのか?
AIモデルの大規模化(GPT-4→Gemini Ultra→今後のモデル群)に伴い、推論・学習コストが指数関数的に膨らんでいます。NVIDIAのH100/B200のような汎用GPU(General Purpose GPU)は「あらゆるAIタスクをこなせる」柔軟性と引き換えに、次のような構造的ボトルネックを抱えています。
| 課題 | 内容 |
|---|---|
| 電力効率 | 汎用設計ゆえに特定ワークロードでは「使われない回路」が電力を浪費する |
| TCO(総保有コスト) | 高単価 × 大量導入 = 数千億〜数兆円規模のCAPEX。トークン生成コスト削減が急務 |
| ベンダーロックイン | NVIDIAのCUDAエコシステムへの依存が、調達・価格交渉力に直結 |
| 帯域幅の壁 | GPU間・ノード間の通信がボトルネック。ネットワーク設計の最適化が競争力を左右する |
カスタムASIC(XPU)とは何か?
カスタムAI ASIC(XPU) とは、特定の企業・特定のAIワークロード専用に設計された半導体です。GoogleのTPU、MetaのMTIA、AmazonのTrainiumがその代表例。汎用GPUと比較して:
- 電力効率が高い(不要な演算回路を省ける)
- レイテンシが低い(特定モデル構造に最適化)
- 長期的なTCOが低い(初期設計コストは高いが、大量展開で逆転)
Broadcomはこの「設計・製造支援」において、SerDes(高速シリアル通信)・先端パッケージング・ネットワークチップの三位一体で他社の追随を許さない立場を確立しつつあります。
【本編】ニュースの核心と技術的優位性
Q1 FY2026決算:数字が語るAI覇権
Broadcomは2026年2月期末の第1四半期において、以下の結果を発表しました。
売上高:$193.1億(前年比+29.5%)、営業利益:$85.6億(+36.8%)、純利益:$73.5億(+33.5%) — Broadcom Q1 FY2026 決算発表より
特筆すべきは半導体部門(Semiconductor Solutions)の急拡大です。
「Semiconductor Solutionsの売上高は前年比54.2%増の$125.2億。AI関連チップがその主要ドライバー」
AIチップ・システム単体では推定**$84.4億(前年比約2倍)**。そのうち約3分の2がAIアクセラレータ+ラックスケールシステム(約$56.5億、前年比2.4倍)、残り約3分の1がAIネットワーキング(約$27.8億)という構成です。
6社のXPU顧客——その正体
Hock TanCEOは以下のコメントとともに、顧客基盤の深さを強調しました。
「我々の6社との協業は、深く、戦略的で、複数年にわたるものだ。SerDes、シリコン設計、プロセス技術、先端パッケージング、ネットワーキングにおける他社に類を見ない技術力を各パートナーに提供し、それぞれの差別化されたLLMワークロードに最適なパフォーマンスを実現する」
業界の観測によると、6社の内訳は以下の通りとされています(一部は推測)。
- Google — TPU v7(Ironwood):2026〜2027年にかけて需要強化。Anthropicも同TPUを$100億規模で調達予定
- Meta — MTIA v2(出荷中)、MTIA v3では「数ギガワット規模」の生産へ
- 顧客4・5 — 2027年に”double”の出荷が見込まれる(ByteDance・Appleと噂)
- OpenAI — 「Titan」XPUをBroadcom経由で製造。FY2027に1GW超の展開予定
「供給側では、2026〜2028年にかけての最先端ウェハ・HBM・基板の確保を完了している。これがパートナーシップの耐久性を担保する」
FY2027に,000億ドルの壁を越えるか
「FY2027のAI収益は、$1,000億を有意に超えることを目標としている」— Hock Tan
過去のAI収益推移を見ると、その成長曲線の急峻さは明白です。
| 年度 | AI収益 |
|---|---|
| FY2022 | $19.3億 |
| FY2023 | $38.1億 |
| FY2024 | $127.4億 |
| FY2025 | $202.5億 |
| FY2026(予測) | 〜$500億 |
| FY2027(目標) | $1,000億超 |
【図解】技術アーキテクチャ・関係図
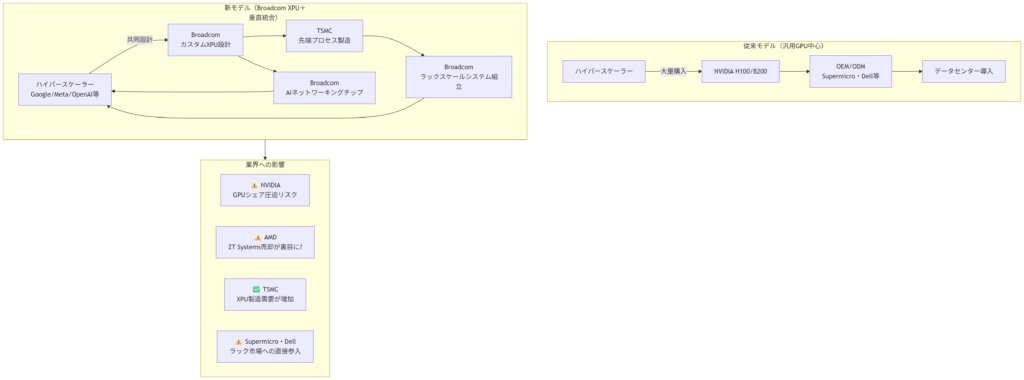
業界地図への影響と投資インプリケーション
📉 脅威を受ける可能性があるプレイヤー
NVIDIA(NVDA) NVIDIAのGPU事業は依然として圧倒的なシェアを誇るものの、ハイパースケーラーによるXPU自社開発シフトが加速すれば、推論用途を中心にシェアが侵食されるリスクがあります。ただし短中期での代替は容易ではなく、学習用途ではNVIDIAの優位性が継続すると推測されます。
AMD(AMD) 記事は「AMDはZT Systems売却を後悔するかもしれない」と指摘しています。Broadcomがラックスケール事業を本格化した際、システム統合能力の欠如がAMDの競争力に影響を及ぼす可能性があります。
Supermicro(SMCI)・Dell・Lenovo等 ラック単位のシステム事業への直接参入は、既存OEM/ODMの中抜きを意味します。Broadcomが「ワンストップ・ショップ」として顧客に訴求できれば、インフラベンダーのAI関連需要が一部代替されるリスクがあります。
📈 恩恵を受ける可能性があるプレイヤー
TSMC(TSM) XPU需要の増大は、最先端プロセス(2nm/3nm)を独占的に提供するTSMCへの製造委託増加につながると推測されます。Broadcomも「2026〜2028年分の最先端ウェハ確保済み」と明言しており、TSMCの長期的な受注積み上げが期待されます。
Marvell Technology(MRVL) 記事では「BroadcomとMarvellが汎用GPUから大きなシェアを奪う」シナリオが言及されています。Marvellも同様のカスタムASICビジネスを展開しており、業界全体の流れから恩恵を受けると推測されます。
Broadcom(AVGO)本体 ソフトウェア(VMware・CA・Symantec)からの安定キャッシュフローを背景に、AI半導体への長期投資を継続できる構造は同社の最大の強みです。FY2027の$1,000億目標の達成可否が、今後の株価評価を大きく左右すると考えられます。
⚠️ 投資判断に関する注意:本記事はテクノロジートレンドの分析を目的としたものであり、特定銘柄の売買を推奨するものではありません。投資判断は必ずご自身の責任のもと、十分な調査を経た上で行ってください。
まとめ
BroadcomはかつてHock Tanが「不要なコストをそぎ落とす職人」として知られたコングロマリットの経営者でしたが、今やAIインフラ時代の「黒幕的プラットフォーマー」へと変貌を遂げつつあります。
カスタムXPUの設計支援、高速ネットワーキングチップ、そしてラックスケールシステムという三層構造で垂直統合を深めるBroadcomの戦略は、「NVIDIAのように自社ブランドで目立つ必要はない、インフラの血管として存在し続ければよい」 という哲学を体現しています。
FY2027に$1,000億というマイルストーンが現実のものとなるかどうか——それはAI投資バブルの持続性とハイパースケーラーの戦略的判断に依存しますが、少なくとも現時点でのモメンタムは、同社が半導体業界の新たな軸となる可能性を十分に示しています。
📎 おすすめの過去記事
NVIDIAのネットワーク事業が驚異的な成長を遂げている背景については、以下の過去記事でも詳しく分析しています。BroadcomとのASIC統合ソリューション対決という文脈でぜひ合わせてご覧ください。
👉 【ニュース解説】【NVDA決算】NVIDIAが12四半期連続の増収記録!ネットワーキング事業が前年比263%増の衝撃——AI時代の”真の覇者”がここにいる
元記事:Broadcom May Become The Biggest Counterbalance To Nvidia


コメント