
※免責事項:本記事はテクノロジー動向の解説を目的としており、投資勧誘を目的としたものではありません。投資に関する最終的なご判断はご自身で行っていただきますようお願いいたします。
エグゼクティブ・サマリー
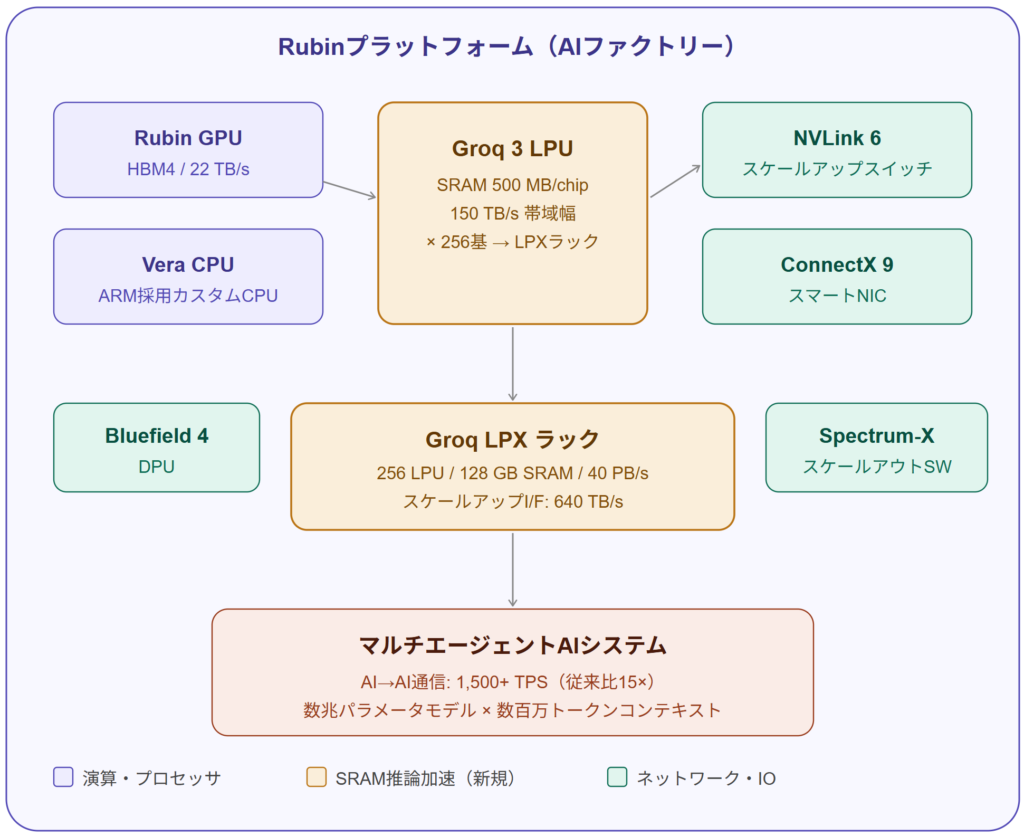
- NVIDIAはGTC 2026基調講演にて、昨年買収したGroqのIP(知的財産)を活用した新チップ「Groq 3 LPU」をRubinプラットフォームに追加し、AIの推論加速器ラインナップを大幅に拡充した。
- Groq 3 LPUは500 MBのSRAMを搭載し、150 TB/sという桁外れのメモリ帯域幅を実現。256基で構成する「Groq LPX」ラックは40 PB/sの帯域幅を持ち、マルチエージェントAIシステムに求められる超低遅延推論を可能にする。
- HBM中心の従来アーキテクチャから「SRAM+HBM」の階層的メモリ構成へのシフトは、AIインフラの設計哲学そのものを書き換える転換点になりうる。
【前提知識】既存テクノロジーの限界と課題
HBMの「帯域幅の壁」
大規模言語モデル(LLM)の推論処理、特にデコード(トークン生成)フェーズは「メモリ帯域幅律速」と呼ばれる状態に陥りやすい。演算ユニット(CUDAコアやTensorコア)がどれだけ速くても、モデルの重みパラメータをメモリから読み出す速度が足りなければ、演算器は手持ち無沙汰になり待機し続ける。
現行世代のRubin GPUに搭載されるHBM4は1チップあたり約22 TB/sの帯域幅を提供する。これは数世代にわたる進化の賜物だが、根本的な制約は変わらない。HBMは「大容量だが、SRAM比では遅い」のだ。
AIエージェント通信が引き起こす新たな需要
人間とチャットボットが対話する従来のユースケースでは、毎秒100トークン程度の生成速度でも十分に実用的だ。しかしマルチエージェントシステム——複数のAIが互いにリクエストを投げ合い、タスクを分解・統合しながら問題を解くアーキテクチャ——では事情が根本的に異なる。受け手もAIである以上、人間が感知できない遅延すら積み重なるとシステム全体のスループットを劇的に下げる。Tom’s Hardwareの報道によれば:
NVIDIAのHyperscale担当VP、Ian Buck氏は「Groq LPUの組み合わせにより、AIエージェント間通信において毎秒100トークンという世界から、1,500トークン以上の世界へ移行できる」と述べた。
この15倍のスループット差こそが、新アーキテクチャの存在意義を端的に示している。
【本編】ニュースの核心と技術的優位性
Rubin + Groq 3 LPUの全体像
Tom’s Hardwareの報道によると、Rubinプラットフォームはこれまでに6種類のチップで構成されていた——Rubin GPU、Vera CPU(ARM採用)、NVLink 6スケールアップスイッチ、ConnectX 9スマートNIC、Bluefield 4 DPU、Spectrum-Xスケールアウトスイッチだ。今回のGroq 3 LPUはその7番目のピースとして加わる。
Groq 3 LPUの技術的差別化要素
Groq 3 LPUの核心は「SRAM大量搭載」にある。1チップあたりのスペックは以下の通りだ(Tom’s Hardware報道より):
| 項目 | Groq 3 LPU | Rubin GPU(HBM4) |
|---|---|---|
| 搭載メモリ容量 | 500 MB SRAM | 288 GB HBM4 |
| メモリ帯域幅 | 150 TB/s | 22 TB/s |
| 用途最適化 | 超低遅延推論(デコード) | 大容量モデル学習・推論 |
容量ではHBMに大きく劣るが、帯域幅では約6.8倍という圧倒的な差がある。
Groq LPX ラックの規模
256基のGroq 3 LPUで構成するGroq LPXラックは:
- 総SRAM容量:128 GB
- 総メモリ帯域幅:40 PB/s(ペタバイト毎秒)
- ラック内スケールアップインターフェース:640 TB/s
このラックがRubin GPUのコプロセッサとして機能し、「AIモデルのすべての層、すべてのトークンにおけるデコード性能を強化する」とIan Buck氏は述べている。
CerebrasとCPXへの戦略的含意
この動きには明確な競合対抗の側面もある。Cerebrasはウェーハスケールエンジン(WSE)にSRAMと演算を大量搭載した低遅延推論専用アーキテクチャで、GPUの「HBMレイテンシの不利」を長年指摘してきた。OpenAIですらCerebrasの容量を確保したとされる中、NVIDIAはGroqのIPを統合することでこの「SRAM/低遅延推論」という差別化ポイントを自プラットフォームに取り込んだことになる。
また、Buck氏はGroq 3 LPUの統合を進める中で既存の「Rubin CPX」推論アクセラレータの役割が縮小する可能性を示唆した。CPXが必要とするGDDR7メモリのコスト・消費電力と比較し、SRAMを直接搭載するLPUのアーキテクチャ的シンプルさが評価されている形だ。
【図解】技術アーキテクチャ・関係図
【エンジニア視点】現場から見る技術の真価と業界への影響
SRAMを「ワーキングメモリ」にすることの本質的な意味
大規模言語モデルの「遅さ」の本質は演算能力ではなくメモリアクセスのパターンにある。LLMのデコードは本質的に「前のトークンを見て次を予測する」逐次処理であり、並列化の恩恵を受けにくい。つまりバッチを積んで演算密度を上げる「訓練フェーズの論理」がそのまま通じない領域だ。
このボトルネックを「演算器を増やす」で解決しようとすると詰まる。むしろ「欲しいデータがすでにそこにある」状態を作ることが正攻法で、それがSRAMの存在意義に直結する。CPUのL1/L2キャッシュがメインメモリの遅延を隠蔽するのと同じ思想が、ここではAIアクセラレータレベルで実装されていると理解すると腑に落ちる。
Groq 3 LPUの「500 MBのSRAMで150 TB/s」という数値を見て、私が最初に頭に浮かんだのはCPUキャッシュのヒット率の話だった。L1キャッシュへのアクセスはメインメモリの100倍以上速い。LLMの推論処理において「アクティベーション」や「KVキャッシュ」をSRAMに乗せておけるなら、HBMへのフォールバックが激減し、帯域幅律速状態から解放される——その設計哲学は極めて正統派だ。
マルチエージェントシステムが変える「遅延の単位」
現場の肌感覚として、人間向けのチャットサービスと、AIエージェントが互いに呼び合うサービスでは「許容レイテンシの桁が違う」という認識は既にある。例えばAPI設計の文脈で言えば、人間が使うUIは数百msの応答時間でも「速い」と感じるが、内部マイクロサービス間の呼び出しなら数十msでも「遅い」と判断されることがある。AIエージェントが他のエージェントにサブタスクを依頼し、その結果をさらに別のエージェントが処理する多段構造では、1ホップあたりの遅延が線形に積み上がるのではなく、複雑なDAG(有向非巡回グラフ)状の依存関係を通じて指数的に影響する。
毎秒100トークンから1,500トークンへという数値は単純な15倍のスループット改善ではなく、「エージェント間通信が実用的になる閾値を超える」という質的変化を意味している可能性がある。オーケストレーションレイヤーの設計者として見ると、タイムアウト設定・リトライ戦略・バックプレッシャー制御など、インフラ設計の前提が大きく変わってくる。
競合への影響とサプライチェーン視点
Cerebrasが突いてきた「NVIDIAのGPUはSRAMが少なく低遅延推論に不利」という論点に対し、NVIDIAはGroq買収という形で真正面から答えた。自前でSRAMアーキテクチャを開発するよりも、すでに実績あるLPU技術を取り込む「IPの水平展開」は、エンジニアリングリソースの観点からも合理的な判断だ。
製造面では、500 MB×256基のSRAMを高集積で実現するにはTSMCの先端プロセスが欠かせず、製造需要の継続が見込まれる。冷却面では、SRAMはHBMよりも電力効率の高いケースもあるが、256基を高密度に並べるラック構成では熱密度管理が新たな課題になる——液冷・冷板技術を持つベンダーへの需要波及も考えられる。
NVIDIAがRubinプラットフォームを「6チップ」から「7チップ」に拡張した事実は、エコシステムとしての垂直統合をさらに深めようとする意志の現れとも読める。ハイパースケーラーがカスタムASICで囲い込みを進める中、標準プラットフォームとしての競争力をSRAM統合で強化するという戦略は、長期的なインフラ選定の議論に影響を与えると個人的には考えている。
まとめ
NVIDIAのGroq 3 LPU統合は、AIアクセラレータの世界に「SRAMファースト推論」という新しい設計思想を本格的に持ち込む動きだ。HBMの大容量と、SRAMの超高帯域を組み合わせる階層的アプローチは、マルチエージェントAIという次の主戦場に向けた布石として理にかなっている。技術的には「帯域幅律速問題」への正統な回答であり、競合対抗策としても明確な狙いが見える。
一方で、500 MB×256という規模のSRAMコストや製造歩留まり、そして実運用での熱設計がどう落ち着くかは今後の動向を注視したい。GTC 2026での発表はあくまでアーキテクチャビジョンの提示であり、実装詳細は続報を待つ必要がある。
おすすめの過去記事
NVIDIAがRubinプラットフォームへの垂直統合を急ぐ背景には、ハイパースケーラーによるカスタムチップ採用という大きなトレンドがあります。その対抗軸を詳しく理解したい方には、こちらの記事もあわせてご覧ください。
👉 【AVGO】BroadcomがNVIDIAの最大の対抗馬へ ——ハイパースケーラーが自社カスタムチップに走る理由と、それがエコシステムに与える構造的変化を解説しています。


コメント