
※免責事項:本記事はテクノロジー動向の解説を目的としており、投資勧誘を目的としたものではありません。投資に関する最終的なご判断はご自身で行っていただきますようお願いいたします。
【エグゼクティブ・サマリー】 NVIDIAはGTC 2026において、LPU(Groq 3)とGPU(Vera Rubin)がデコード処理を層単位で分担する「物理的役割分離アーキテクチャ」を今年中に出荷すると明言した。CPXの延期はこの実装への集中を意味し、経済的に実現不可能だった「毎秒1,000トークン生成」を現実的なコストで達成する可能性を示している。また、Vera CPUはx86の代替ではなく、エージェントAIの「クリティカルパス」を埋める専用演算ユニットとして位置づけられた。
既存テクノロジーの限界と課題
LLMの推論処理における最大のボトルネックは、デコードフェーズの「メモリ帯域幅律速」にある。
トークンを1つ生成するたびに、モデルの全重みパラメータをメモリから読み出す必要がある。GPUが搭載するHBM(High Bandwidth Memory)は大容量(Vera Rubin NVL72では280GBクラス)だが、SRAMと比較するとメモリ帯域幅には物理的な上限がある。
Groqが開発したLPUはSRAMベースのアーキテクチャであり、HBMの約7倍の帯域幅を持つとされる。しかし、LPUの弱点はSRAMの容量制限(1チップあたり500MB程度)にあった。モデルの重み・KVキャッシュ・マルチクエリの状態を全てSRAM上に保持しようとすると、1兆パラメータ規模のモデルでは「数十ラック分のLPU」が必要となり、経済的に成立しない。
すなわち、従来のアーキテクチャには次の二律背反があった。
- GPUのみ: 大容量・低コストだが、帯域幅の制約でトークン生成速度に限界がある
- LPUのみ: 超高速だが、容量不足により大規模モデルでは膨大なチップ数が必要でコストが見合わない
この物理的なジレンマを解消するために、NVIDIAが採用したアプローチが「層単位の演算分離(Layer-wise Disaggregation)」である。
ニュースの核心と技術的優位性
Tom’s Hardwareの報道によると、GTC 2026の翌日に開催されたプレスQ&Aセッションで、NVIDIA VP of Hyperscale and HPCのIan Buck氏が以下の核心的な内容を明かした。
LPUとGPUによるデコードの層単位分担
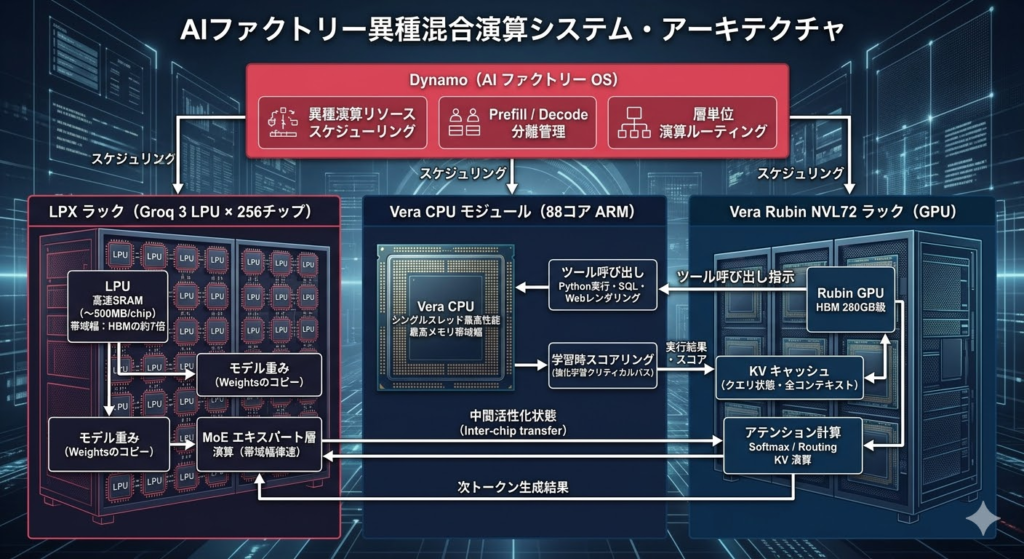
「デコードはLPUとGPUの間で実際に分割されます。LPUの高速なSRAMが恩恵を受ける演算はLPU側で実行し、文字通り次の層では中間活性化状態をGPUに送信してアテンション計算・softmax・ルーティング・KV計算を行わせます。重みのコピーはLPUだけが保持すれば良く、クエリごとの状態やKVキャッシュ状態はHBM上に置けます。」
これはトランスフォーマーモデルの演算グラフを「帯域幅律速の層(MoEのエキスパート層など)」と「状態依存の層(アテンション機構)」に分類し、それぞれを最適なハードウェアに割り当てるというアーキテクチャ上の分業である。
CPX延期の真相
Ian Buck氏は「LPUデコードの実装に今年のリソースを集中させるためにCPXを延期した」と明言した。CPXはプリフィルフェーズ(最初のトークンを生成するまでの時間)の最適化を目的としていたが、同氏は「プリフィルは既存ハードウェアで解決できる問題であり、その後の全トークン生成速度を高めることの方が優先度が高い」と説明した。
「LPUデコードは最初のトークン以降の全トークンの速度を向上させます。」
Vera CPUの戦略的役割
Vera CPUは88コアのARMベースCPUであり、NVIDIAは「世界最高のエージェント用CPU」と位置づけている。その理由として示されたのは以下の用途である。
- モデルの学習中に生成されたコードをCPU上で実行し、その精度をスコアリングしてGPUに返すことで、GPUをアイドルにさせない(強化学習ループのクリティカルパスへの対応)
- 推論時にAIエージェントがSQLクエリ実行・Webレンダリング・Pythonインタープリタ起動などのツール呼び出しを行う際のホスト演算
- エージェント同士が人間を介さずマシン速度で通信し合うマルチエージェント環境における高スループット処理
Ian Buck氏は「$300億・1ギガワットのGPUデータセンターを持ちながら、CPUがボトルネックでGPUをアイドルにさせることはあり得ない」と述べており、Vera CPUはGPUの投資対効果を最大化するための補完的存在として明確に定義されている。
DynamoによるソフトウェアレイヤーとNVLink Fusion
LPUとGPU間の演算分離を実現するソフトウェア基盤として、NVIDIAの「Dynamo」(AI ファクトリーのOSと位置づけられる)が活用される。GroqのソフトウェアチームはすでにDynamoチームに統合されており、1日約100件のGitHubコントリビューション(うち約3分の1が外部からの貢献)を受けているとされる。
IntelとのNVLink Fusionパートナーシップについては、「シリコンレベルの統合が進行中であり、近く追加のアナウンスがある」とBuck氏は述べた。ただし、現行のGroq 3(LP30)にはまだNVLink チップ間インターコネクトは搭載されておらず、次世代LP40での実装が予定されている。
【図解】技術アーキテクチャ・関係図
【エンジニア視点】技術の真価と業界への影響
層単位分離(Layer-wise Disaggregation)の技術的意義
今回の最大のポイントは、「プリフィルとデコードの分離(既存のDisaggregated Serving)」からさらに一歩踏み込んで、「デコード処理の内部をトランスフォーマー層の特性に基づいて分割する」という粒度の細かさにある。
トランスフォーマーの演算はざっくりと以下の2種類に分類できる。
- MoEのFFN(Feed-Forward Network)層: 重みの読み出しが支配的で、メモリ帯域幅律速。モデルの重みをSRAMに保持できれば超高速に処理できる
- アテンション機構: KVキャッシュと入力トークン全体を参照するため、大容量メモリが必要。演算自体よりもデータの「在り処」が重要
LPUをFFN層の専用プロセッサとして使い、KVキャッシュは全てHBM(GPU側)に保持するという設計は、両者の物理的特性を最大限に活かす合理的な割り当てである。これにより「重みのコピーはLPUだけが持てば良い」という設計になり、必要なLPUの数が劇的に削減される。Ian Buck氏が示したように、「数十ラックのLPX」が「2ラックのLPX + 1ラックのVera Rubin」で同等の性能を達成できるという試算は、この層単位分離の直接的な効果である。
Vera CPUの設計哲学とエージェントAIの構造的要件
従来のサーバーCPUは「多コア・高スループット・仮想化」を最優先としてきたが、エージェントAIのワークロードが要求するのは「シングルスレッドの絶対性能」と「全コアを使い切ったときのメモリ帯域幅の持続性」である。
強化学習(RLHF・GRPO等)における「コード生成 → 実行 → スコアリング → フィードバック」のループは、GPU側の学習処理と密結合しており、CPUのレイテンシが直接モデルの収束速度に影響する。これはSampling Efficiencyの問題ではなく、純粋にシステムボトルネックの問題であり、$300億規模のGPUクラスタの稼働率をCPU性能が規定するという構造は、データセンター設計において無視できない問題となっていた。
Vera CPUはこの課題を解決するための専用設計であり、汎用x86を置き換えるものではなくGPUの「補助演算コプロセッサ群」として設計されている点は、戦略的に整合している。
NVLink Fusionとインターコネクトの覇権
NVLinkをCPU側に拡張するFusionの戦略は、PCIeというボトルネックを排除してGPU-CPU間帯域幅を10〜20倍に引き上げるものである。これが普及すると、「GPU側の演算とCPU側のツール実行の往復レイテンシ」が劇的に削減され、エージェントAIの応答性に直接寄与する。
現行のLP30(Groq 3)にはまだNVLinkインターコネクトが搭載されておらず、LP40で実現予定とされている。この点は、現段階での「LPU-GPU間の転送コスト」が将来世代で更に改善される余地があることを示唆している。
競合他社への影響という観点
「毎秒1,000トークン・1兆パラメータモデル・40万〜50万トークンのコンテキスト」という性能要件は、AIエージェントが人間を介さずマシン速度で動作するシナリオを想定したものである。この要件を経済的に満たすアーキテクチャを持つのが現時点ではNVIDAのLPX+Vera Rubin構成に限られるとすれば、フロンティアラボのインフラ調達における選択肢が構造的に制約される可能性があるという見方もできる。ただし、他社(AMD・Intel・独立系AIチップベンダー)がどのようなアーキテクチャで対抗するかによって、市場の勢力図は変化し得る。
ソフトウェアエコシステムとしてのDynamo
1日100件のGitHubコントリビューションのうち3分の1が外部由来というデータは、Dynamoがオープンな開発者エコシステムを形成しつつある可能性を示す。ただしIan Buck氏自身が述べているように、「同じGPUでもソフトウェア最適化だけで4ヶ月・120万GPU時間の探索の末に4倍の性能向上を達成した」という事実は、ハードウェア性能の比較だけでは実際の推論効率を評価できないことを示しており、スタック全体の最適化深度が競争力を決定するという構造が一層強まっているといえる。
まとめ
GTC 2026でNVIDIAが公開したLPU-GPUハイブリッドアーキテクチャの核心は、「トランスフォーマーの演算特性に基づく層単位の物理的役割分担」にある。LPUのSRAM(高帯域幅・低容量)でMoE層の重み演算を行い、GPUのHBM(大容量)でKVキャッシュとアテンション演算を処理するという分業は、それぞれのハードウェアの物理的優位性を最大限に活かす合理的な設計である。
CPXの延期はこのアーキテクチャへの資源集中を意味し、Vera CPUはGPUのクリティカルパスを補完する専用演算リソースとして明確に位置づけられた。DynamoによるソフトウェアレイヤーとNVLink Fusionによるインターコネクト戦略を含め、NVIDIAのAIインフラ戦略はハードウェア単体の優位性から「異種演算リソースの統合最適化」へと重心を移しているといえる。
このアーキテクチャが実際の市場でどのような受容を得るかは、今後の出荷状況・サードパーティの採用動向・競合他社の対抗アーキテクチャによって変わり得る点には注意が必要である。
おすすめの過去記事
NVIDIAによるGroq LPUのRubinアーキテクチャへの統合については、以前の記事でその買収背景と戦略的意図を解説しています。
今回明かされた「LPUとGPUが層単位でデコード処理を分担する」という具体的な実装詳細と合わせて読むと、NVIDIAのエンドツーエンド推論戦略の全体像がより鮮明になります。ぜひ過去記事もご参照ください。


コメント