
※免責事項:本記事はテクノロジー動向の解説を目的としており、投資勧誘を目的としたものではありません。投資に関する最終的なご判断はご自身で行っていただきますようお願いいたします。
エグゼクティブ・サマリー
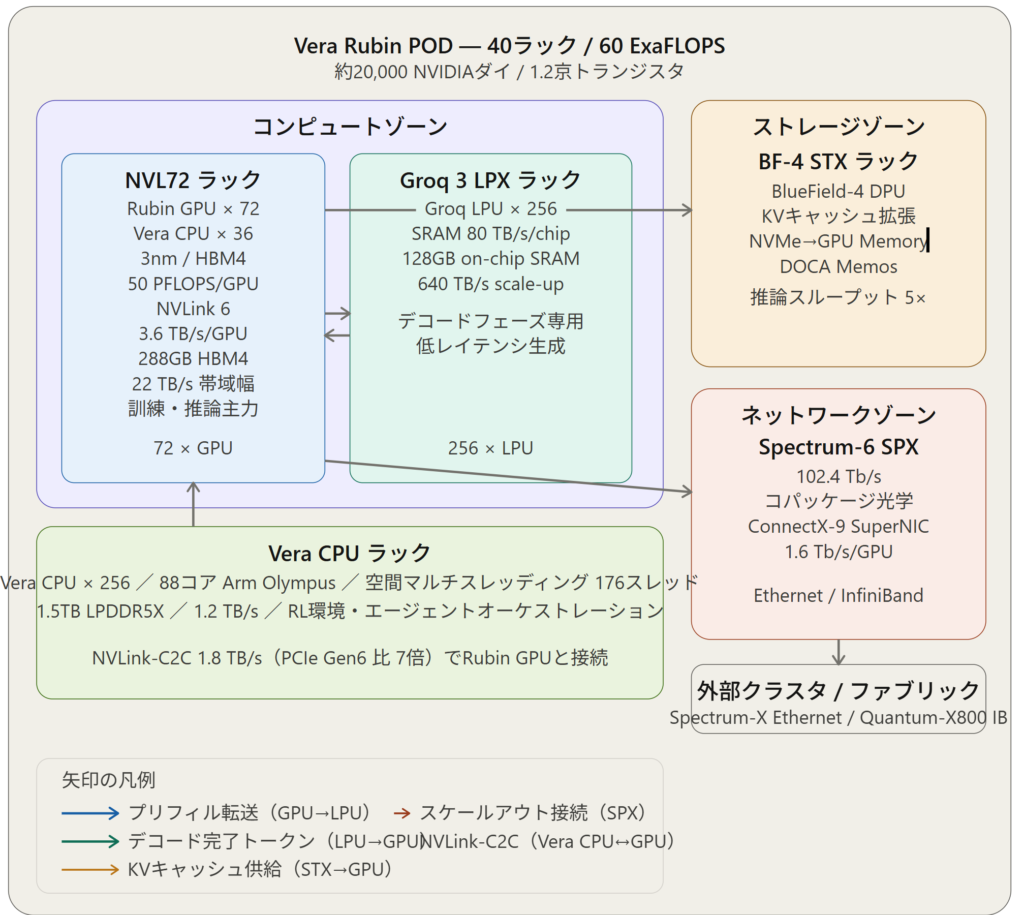
NVIDIAはGTC 2026において、GPU単体の時代を終焉させる「AIファクトリー」という新たな提供単位を正式に宣言した。7種類のシリコン(GPU・CPU・LPU・NVLinkスイッチ・SuperNIC・EthernetスイッチASIC・DPU)が5種類のラックに分散配置され、40ラック規模のPODとして60エクサフロップスを実現する垂直統合型スーパーコンピュータが2026年後半に出荷予定だ。特筆すべきは、2025年12月にNVIDIAが約200億ドルで買収したGroqの「LPU」がRubinエコシステムに正式統合された点であり、推論フェーズのアーキテクチャが根底から刷新される。
【前提知識】既存テクノロジーの限界と課題
なぜGPU単体では限界が来ているのか
大規模言語モデルの推論には、大きく2つのフェーズが存在する。プリフィル(prefill)フェーズ(入力コンテキストを一括処理)と、デコード(decode)フェーズ(トークンを逐次生成)だ。この2つは求められる性能特性が根本的に異なる。プリフィルは並列演算能力(FLOPS)を要求し、デコードはメモリ帯域幅とレイテンシを要求する。現行のGPUはどちらも”そこそこ”こなせるが、デコードフェーズにおいては構造的な非効率が避けられない。
HBM(High Bandwidth Memory)は確かに広帯域だが、その帯域幅はチップとメモリダイの物理的距離・層数に制限される。Rubin GPUが搭載するHBM4でも22 TB/sという数字は驚異的だが、推論トークン生成の反復的なメモリアクセスパターンに対し、SRAMのような真のオンチップ帯域とは次元が異なる。
また、コンテキストウィンドウの長大化(数十万〜数百万トークン)に伴い、KVキャッシュのサイズが爆発的に増大している。このKVキャッシュをGPUのHBMに収めきれなくなると、パフォーマンスが急落するか、GPUをひたすら積み増すしかなかった。これが現行Blackwellベースのシステムが抱える構造的ボトルネックだ。
【本編】ニュースの核心と技術的優位性
Tom’s Hardwareの報道によると、NVIDIAはGTC 2026において「AIファクトリー」を構成する7種類のチップを正式に量産発表した。ここでは各チップの役割を順に解説する。
① Rubin GPU ― 訓練・推論の主力エンジン
TSMCの3nmプロセスを採用したデュアルダイ設計で、3360億トランジスタを搭載。288GBのHBM4メモリと22 TB/sの帯域幅を備え、NVFP4フォーマットで50 PFLOPSの推論性能と35 PFLOPSの訓練性能を実現する。これはBlackwell比でそれぞれ5倍・3.5倍の向上だ。
NVL72ラックでは72基のRubin GPUをNVLink 6で接続し、単一の巨大アクセラレータとして振る舞う。Tom’s Hardwareの報道によると、
NVL72はMixture-of-Expertsモデルの訓練においてBlackwellの4分の1のGPU数で実現可能とされ、推論トークンコストは10分の1に削減できるとNVIDIAは主張している。
② Vera CPU ― NVIDIA初の自社データセンターCPU
88コアのカスタムArm「Olympus」コアと空間マルチスレッディング(Spatial Multithreading)技術により176スレッドを実現。最大1.5TBのSOCAMM LPDDR5Xメモリを搭載し、1.2 TB/sのメモリ帯域幅を誇る。
Rubin GPUとはNVLink-C2C(1.8 TB/s)で接続されており、これはPCIe Gen 6比で7倍の帯域幅だ。Veraの主な役割は「オーケストレーション」——KVキャッシュのルーティング、エージェントAIのコントロールプレーン管理、強化学習環境の実行だ。
③ Groq 3 LPU ― デコードフェーズの超低レイテンシ専用チップ
今回最も驚きをもって迎えられたのがこのチップだ。各LPUは約500MBのスタックSRAMを搭載し、1チップあたり約80 TB/sの帯域幅を実現する。256基のLPUで構成されるGroq 3 LPXラックは128GBのオンチップSRAMアグリゲートと640 TB/sのスケールアップ帯域幅を持つ。
プリフィルはRubin GPUが担い、デコードはGroq 3 LPUが引き継ぐ——この役割分担により、NVIDIAは「1メガワットあたりの推論スループット35倍向上、兆パラメータモデルで10倍の収益機会創出」を主張している。
④⑤⑥ 三種の専用ネットワーキングASIC
NVLink 6スイッチはラック内スケールアップ接続を担い、GPUあたり3.6 TB/sの双方向帯域幅を提供。9枚のスイッチトレイでNVL72ラックに260 TB/sのアグリゲートスケールアップ帯域幅を供給する。さらに14.4 TFLOPSのFP8インネットワーク演算でMoEのall-to-all通信パターンを加速する。
ConnectX-9 SuperNICはGPUあたり1.6 Tb/sでラック間スケールアウト接続を提供。Spectrum-X EthernetまたはQuantum-X800 InfiniBandファブリックを通じてNVL72を多ラッククラスタに連結する。
Spectrum-6 Ethernetスイッチは102.4 Tb/sのアグリゲート帯域幅を実現し、NVIDIAとして初のコパッケージ光学(Co-Packaged Optics)を採用。シリコンフォトニクスにより光学系の消費電力を削減し、前世代Spectrum-X比で電力効率5倍・レジリエンス10倍を謳っている。
⑦ BlueField-4 DPU ― インフラオフロードの司令塔
64コアGrace CPUとConnectX-9 NICを統合したデュアルダイパッケージ。ネットワーク処理、ストレージ暗号化、仮想スイッチング、セキュリティ施行をGPU・CPUの処理経路から完全にオフロードする。BlueField-3比で帯域幅2倍、メモリ帯域幅3倍、演算性能6倍。
このBlueField-4がBlueField-4 STXストレージラックを支え、NVMeストレージをGPUメモリの延長として扱う「CMXコンテキストメモリストレージ」プラットフォームを実現。KVキャッシュのボトルネックを打破し、推論スループットを最大5倍向上させるとされる。
【図解】Vera Rubin POD 技術アーキテクチャ関係図
【エンジニア視点】現場から見る技術の真価と業界への影響
NVIDIAが今回発表した内容は「新しいGPUが出た」という話ではまったくない。コンピューティングの「販売単位」の再定義だ。
GPUからラック、そしてPODへ ― 設計哲学の転換
かつてのデータセンター設計では、サーバーの仕様を決め、ラックに積み込み、ネットワークスイッチで繋ぐという分業体制が標準だった。しかし現場のエンジニアとして痛感してきたのは、AIワークロードにおけるボトルネックが「GPU性能」ではなく、しばしば「GPU間・ノード間のデータ移動コスト」であるという現実だ。
AllReduceの通信オーバーヘッド、KVキャッシュのスラッシング、PCIeによるホストCPU↔GPU間のデータ転送レイテンシ——これらはGPUをどれだけ速くしても消えない構造的問題だった。Vera RubinのアーキテクチャはこれをNVLink-C2C(1.8 TB/s)、in-network compute(NVLink 6スイッチ上での14.4 TFLOPS)、そしてBlueField-4によるオフロードで「チップ間インターコネクト」レベルで解消しようとしている。
Groq LPU統合の衝撃 ― 推論アーキテクチャの根本的再設計
個人的にもっとも驚いたのが、Groq 3 LPUのプラットフォーム統合だ。現場での推論システム構築において、プリフィルとデコードを同一GPUで処理することの非効率さは常に課題だった。プリフィルはバッチ処理に向いており、デコードは逐次的・インタラクティブな処理だ。これを同じハードウェアに押し込むことで、どちらのフェーズも最適化できないというジレンマが生じる。
Groq LPUはSRAMベースのアーキテクチャにより、HBMとは次元が異なる帯域幅(80 TB/s/chip)を実現する。ただしSRAMはHBMに比べ単位容量あたりのコストが高く、容量自体も限られる(LPXラック全体で128GB)。これは「容量よりも速度」を優先するデコードフェーズ専用として割り切った設計であり、Rubin GPUとの役割分担が非常に合理的だ。現場感覚として、この組み合わせはリアルタイム性を要求するエージェントAIアプリケーション(対話システム、コード生成、マルチステップ推論)で大きな威力を発揮すると考えられる。
Vera CPUとARMエコシステムへの影響
NVIDIAが独自ARMコア「Olympus」を搭載したVera CPUを出してきたことは、データセンターCPUの勢力図に無視できない影響を与える可能性がある。空間マルチスレッディング(Spatial Multithreading)は、時間分割ではなく物理リソースの専有により2スレッドの真の並行実行を実現する技術で、エージェントAIのPython制御フローや強化学習環境のような「CPU的なタスク」での性能向上を見込む設計だ。
NVLink-C2C(PCIe Gen 6の7倍)によるホスト↔GPU間のコヒーレント接続は、従来のPCIeベースの構成では到底実現できなかったデータ転送効率をもたらす。これは汎用サーバーCPUとの組み合わせと比較して、アーキテクチャ的な優位を持つことを意味し、AMDやIntelのホストCPUシェアを侵食する可能性を内包している。
Spectrum-6とコパッケージ光学 ― 電力問題への本質的アプローチ
データセンターにおける光学トランシーバの消費電力は見過ごされがちな問題だ。大規模クラスタでは光トランシーバモジュール群だけで数百kWのオーダーに達することもある。Spectrum-6がコパッケージ光学(シリコンフォトニクス)を採用したことは、この電力コストに直接アプローチする意義がある。「5倍の電力効率改善」というNVIDIAの主張が事実であれば、クラスタ全体のPUE(電力使用効率)改善への貢献は無視できない。
サプライチェーンと業界構造への示唆
60エクサフロップスのPODには約1.2京個のトランジスタが詰め込まれている。TSMCの3nmプロセスへの依存はより鮮明になっており、先端ロジック製造における地政学的リスクが業界全体の懸念事項として残り続ける。
一方、液冷システムの標準化(Rubin世代では液冷が事実上必須)は、冷却・サーバーインフラベンダーの恩恵を受ける可能性がある構図として注目に値する。また、NVIDIAが自社設計のEthernetスイッチ(Spectrum-6)とDPU(BlueField-4)を垂直統合する流れは、従来これらの市場を担ってきたベンダーとの競合激化を示唆している。
エンジニアとして残る疑問
このアーキテクチャが優れているのは間違いない。しかしいくつかの疑問が残る。
ひとつはソフトウェアスタックの成熟度だ。DOCA Memosによるオフロードや、プリフィル・デコードの分散処理最適化は、理論上の数字が現実のワークロードで再現されるためにアプリケーション側の対応が不可欠だ。7チップ協調動作のチューニングは容易ではない。
もうひとつはTCO(総所有コスト)だ。60エクサフロップスのPODに必要なラック電力・冷却インフラ・スペースの規模は並大抵ではない。実際にこれを導入できるのはGoogle Cloud・AWS・Azure・Meta・xAIといったごく限られたハイパースケーラー群に限られると見られ、エンタープライズへの波及は数世代後になるのが現実的な見立てだ。
まとめ
Vera Rubin PODは、NVIDIAが「AIファクトリー」として提唱するシステム統合の集大成だ。7種のシリコンが1つのコデザイン済みシステムとして動作し、40ラック・60エクサフロップスを単一の購入・展開単位として提供する。特にGroq 3 LPUの統合による「プリフィル/デコード分離アーキテクチャ」と、BlueField-4 STXによるKVキャッシュ問題の解消は、兆パラメータモデル時代の推論コスト構造を塗り替えうるインパクトを持つ。
2026年後半の出荷開始に向け、ソフトウェアエコシステムの整備状況とハイパースケーラーの採用動向が次の注目点になるだろう。
おすすめの過去記事
本記事で解説したGroq 3 LPUとSRAMがもたらす推論革命のより深い背景については、ぜひ以下の記事もご覧ください。
👉 NVIDIAがGroq LPUをRubinに統合——SRAMがAIエージェント時代のレイテンシ革命を引き起こす
NVIDIAがどのような経緯でGroqを買収し、そのLPUアーキテクチャがRubinプラットフォームに与える意味を詳細に解説しています。
元記事とLink
Tom’s Hardware
“Examining Nvidia’s 60 exaflop Vera Rubin POD — how seven chips underpin company’s 40 rack AI factory supercomputer”
🔗 記事を読む(Tom’s Hardware)
発行日:2026年3月17日


コメント